
这段时间,AI领域里,一个名为MoE的模型,把圈子给刷屏了,为了实现与Llama 2 - 7B相类似的性能,其靠着百分之四十的计算成本达成了目标,结果一下子就成了开源社区里新被宠爱的对象了。
模型性能表现
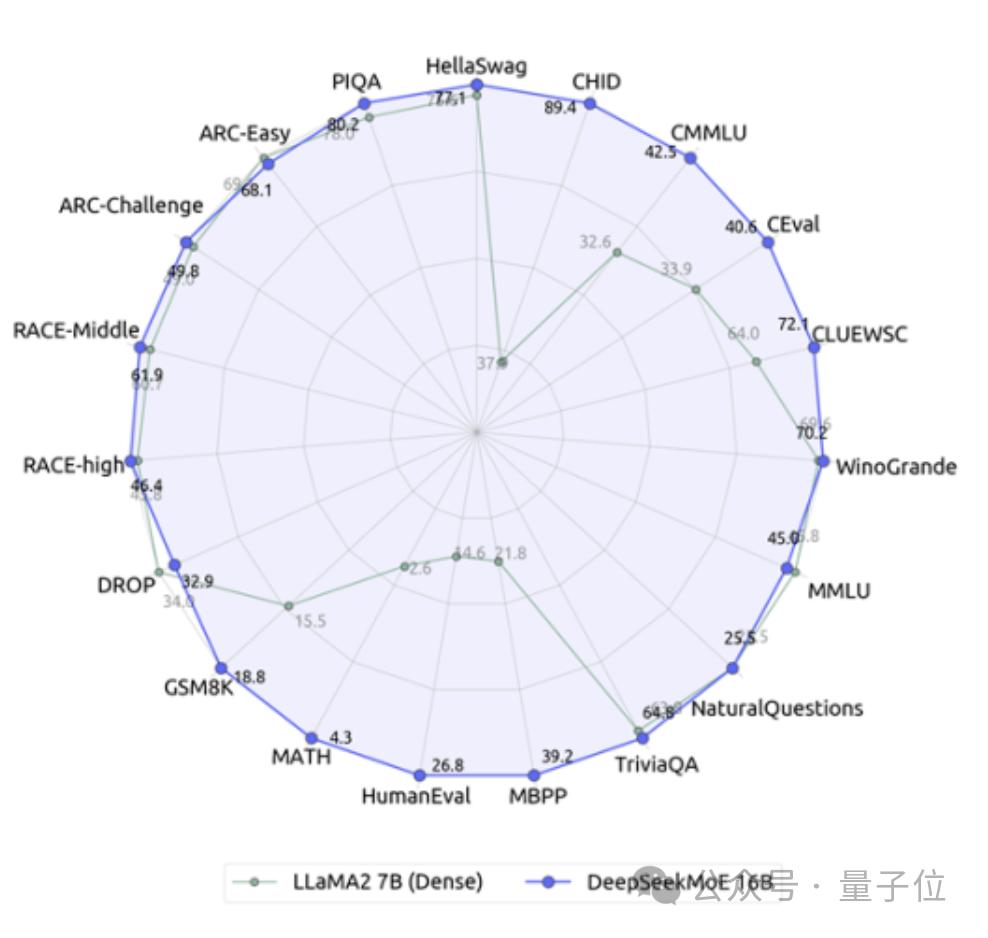
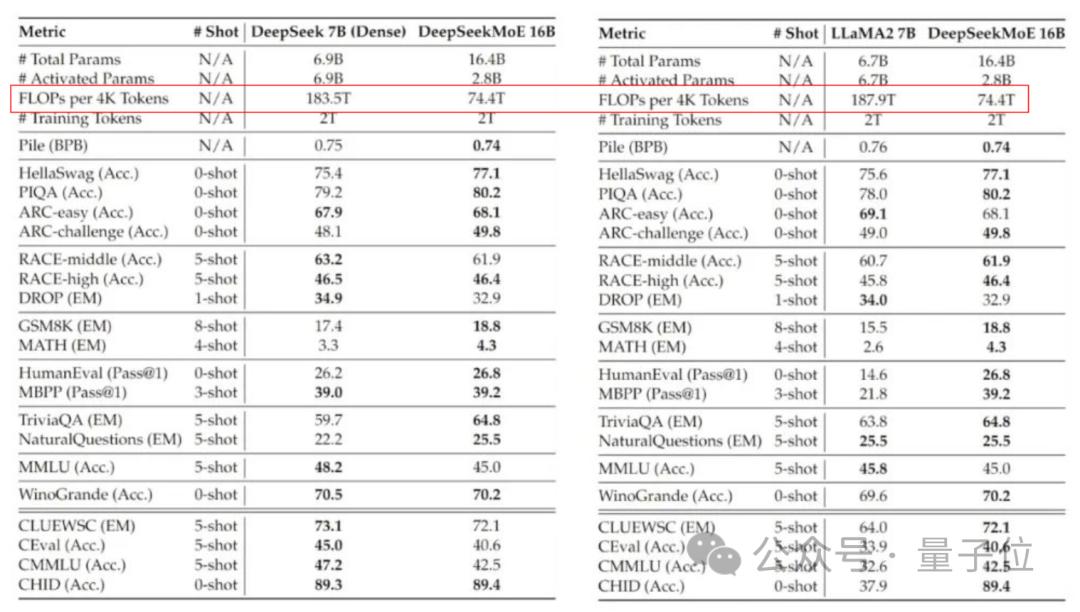
模型在多项测验里呈现出卓越的能力展露光彩,其在数学解题以及代码生成的活动任务当中超乎寻常地处大于相同数目层次的传统类型的模型,在一些测验的成果里甚至是接近于拥有更多参数数量的模型的等级水准,实际运用得到的数据表明此番模型在处理复杂数学问题时显示为正确的比率相较于名叫Llama 2-7B的模型要高出十五个百分百的点数之多 。
于代码编写能力测试期间,MoE在Python算法题解答方面,展现出极为出色的表现。有开发者给出反馈,此模型能够精准地领会编程需求,进而生成契合规范的代码片段。经过多位业内人士的验证之后,他们觉得,这个具备160亿参数的模型确实达成了预期的设计目标。
计算效率突破
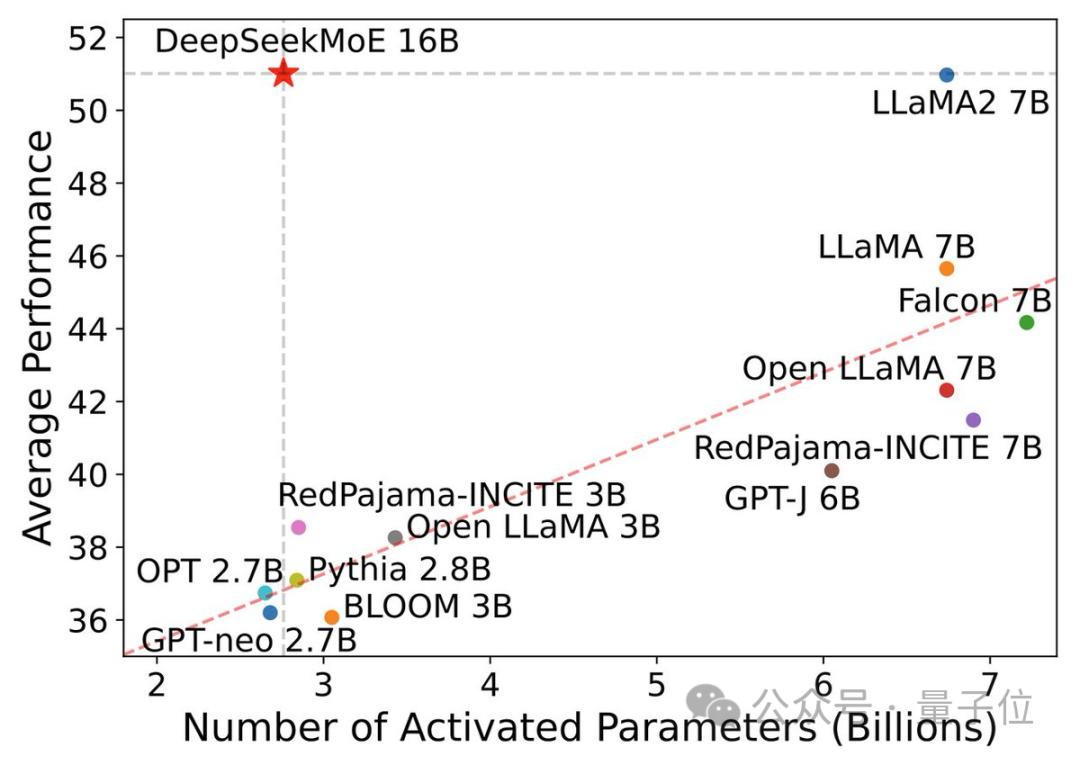
最能吸引他人目光的MoE模型特色,是它厉害的计算效率,在对接相同规模任务的时候呢,该模型用到了只有Llama 2 - 7B模型40%的计算资源,具体的数据是这样展现让大家知晓,每次对4千单位计算量的情况来看,传统模型所需的计算量超过100单位,然而这里的MoE模型仅仅只用得起需求74单位计算量。
这种高效率致使个人开发者能于寻常硬件之上运行大型语言模型。有用户实际测试表明,在单张消费级显卡那儿就能够顺畅运用 MoE 模型,这般大大削减了 AI 技术的使用门槛。计算资源极大地缩减,这为模型部署带来全新可能了 。
开源社区反响
开源的社区对着个全新的模型展现出极大的热情,于GitHub平台之上,MoE项目上线没有多久就获取到多于300个的星标,快速地登上热门榜单。开发者们积极地测试起模型的性能,并且在讨论区分享使用的体验。
社交平台上,诸多机器学习工程师发表了测试结果,一位来自JP摩根的工程师证实,MoE的聊天版本在表现方面确实要比微软的Phi-2小模型更加出色,社区当中普遍觉得这是今年最具实用价值的开源模型之一 。
模型架构创新
有着创新的专家混合架构的MoE取得成功,是源于此架构,跟别种传统密集模型不一样,它先是把网络划分成多个专业化的“专家”,随着处理每个任务之时,系统依靠智能去选择最相关的专家组合,让其参与计算 。
在于这种设计的精妙之处是,模型总参数量达160亿之际 ,每回推理却仅仅激活约28亿参数 。这意味着模型既有很庞大的知识储备 ,又能够维持高效的计算性能 。而且这种架构在保证了效果前提下,尤其明显地降低了关于资源的需求 。
共享专家机制
团队于MoE里引入了别具一格的共享专家设计,如此这般的共享专家不间断地处理全部输入信息,承担起提取通用特征以及基础知识的职责,这般机制保证模型对常见模式存有一致理解。
专注于各自擅长领域的专项专家,在需要之时被激活从而参与计算。消融实验证实,这样一种共享与专项相结合的设计,将参数利用效率显著提高。模型借此能够以更少的计算量来完成更为复杂的任务。
未来发展前景
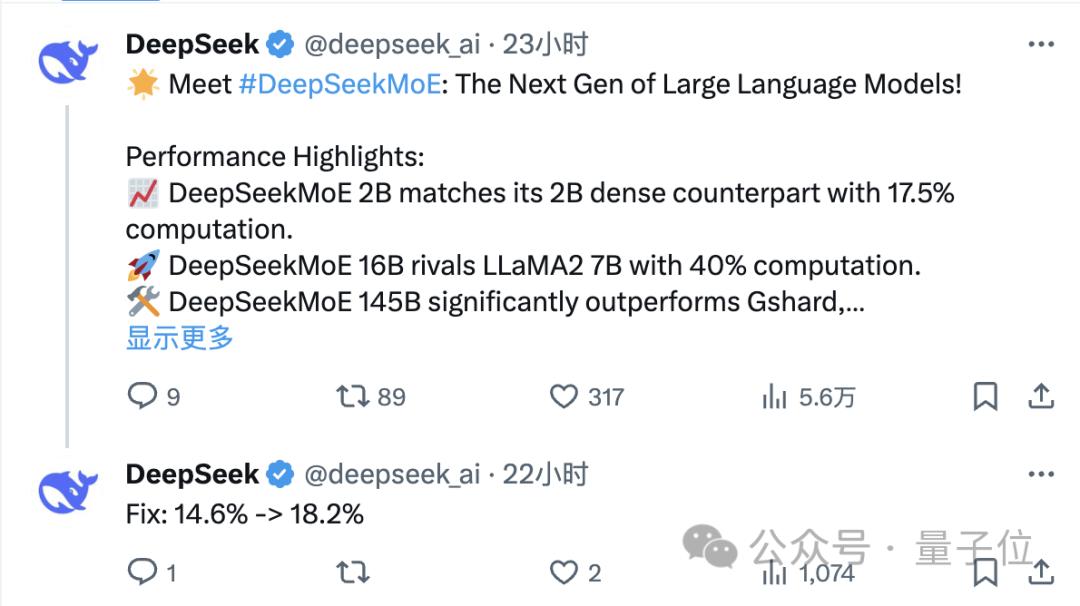
深度求索团队透露了正在开发大型MoE模型,该模型具有145B参数。初步测试数据显示,新模型仅用28.5%的计算量,就能达到67B密集模型的性能能级。这表明MoE架构在未来还有巨大的发展空间,没错吧。
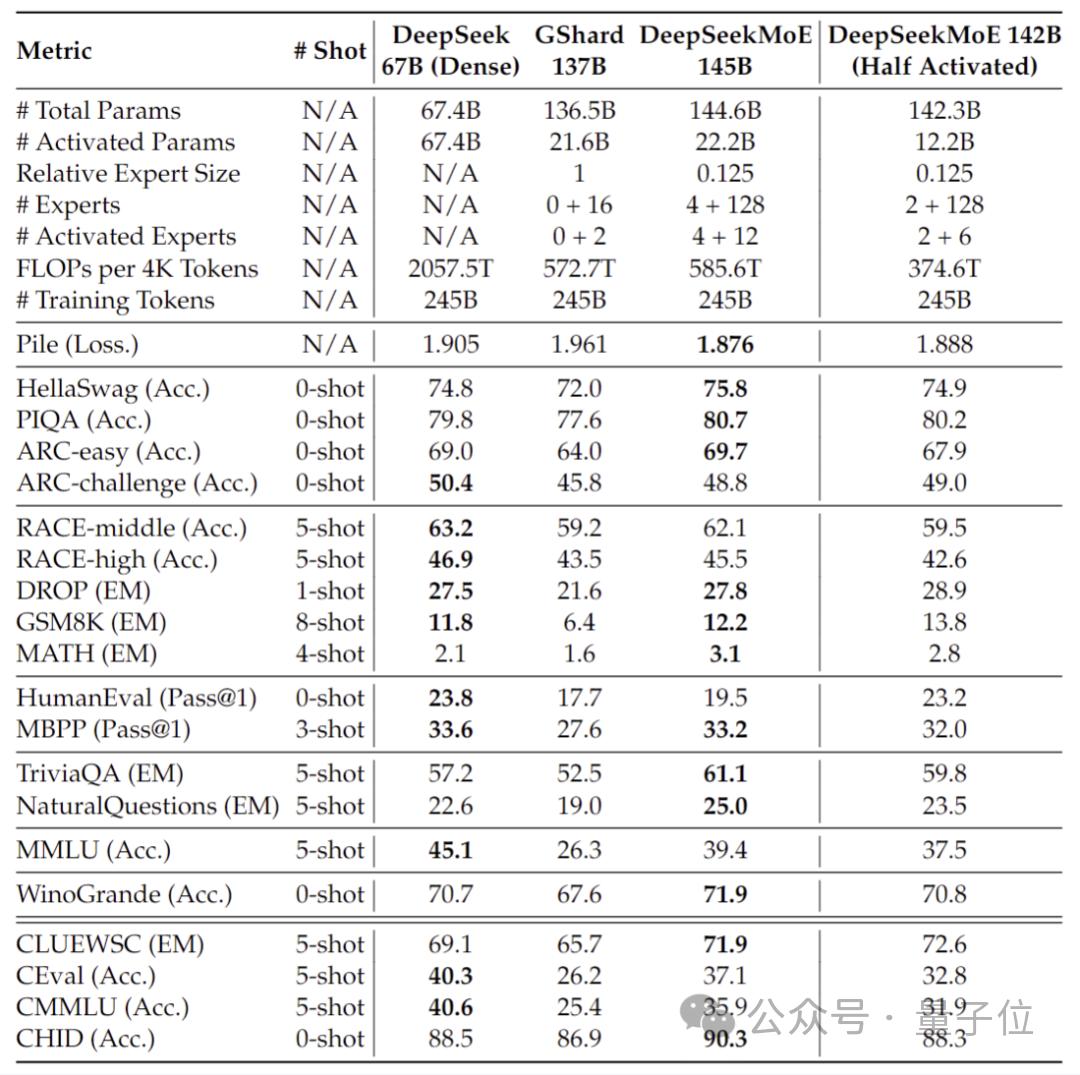
模型规模持续扩大的情况下,这种被认为高效的架构,具备改变AI行业游戏规则的较大可能性。越来越多的研究团队,留意并着手跟踪这个技术路线,预估未来会有更多以MoE架构为基础的变体模型出现 。
实际工作里头,你最为看重的AI模型特性究竟是什么:是其具备的极高准确率这一特性呢,还是更快的响应速度这一特性呀?假如你觉得本文对自己有帮助的话,那就请在评论区将你的观点分享出来,并且点赞予以支持吧!
发表评论