
大语言模型对长文本进行处理之际,计算量似狂风骤起般呈平方级爆增不止,这情况已然成为行业迈向发展之路的瓶颈阻碍。到底有没有办法巧妙绕开这个棘手难题呢?有一种被称作“光学压缩”的全新思路正犹如暗夜里的星火开始引发众人的密切关注。
光学压缩的基本原理
传统的文本处理,是要逐个去分析词语的,视觉信息是可以同时承载不少内容的。把文字转变成图像之后,原本得用上千个的文本单元去表达的内容,现在仅仅数百个视觉单元就能够完整呈现出来了。
这种方法对人类阅读之际的整体感知方式予以了模仿,我们在看一页书的时刻,能够同时将版面布局、段落间距等视觉线索进行捕捉,而这些信息,均对于理解内容有所助益,光学压缩恰恰就是利用了这般特点,借由视觉模态给文本信息实施“瘦身” 。
核心架构设计
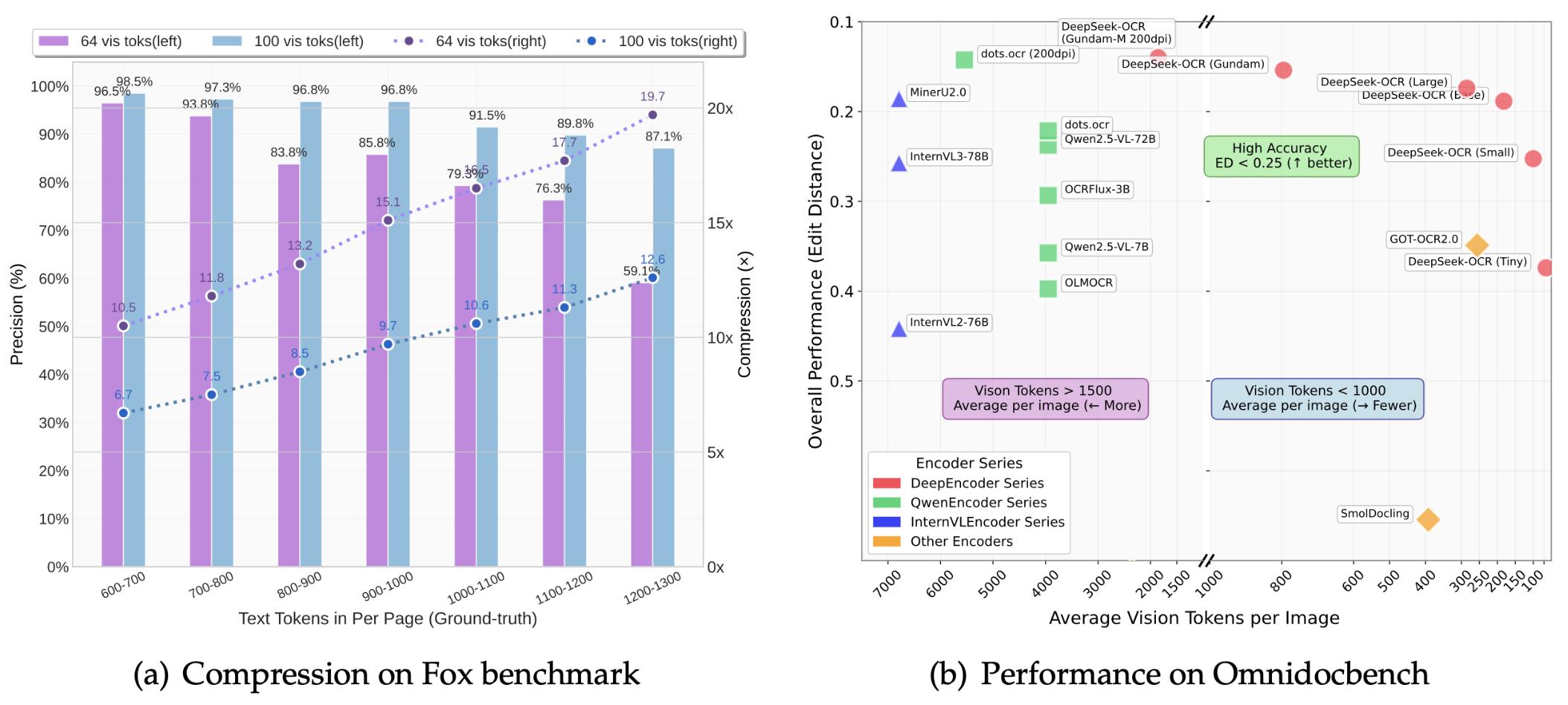
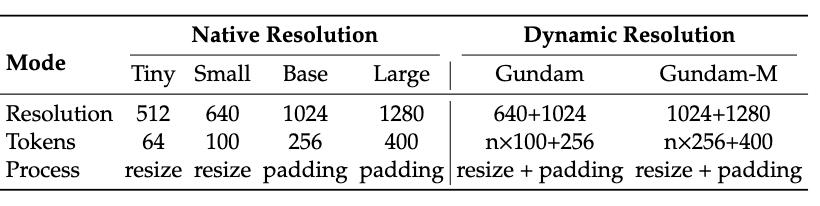
该项技术运用的是分段处理架构,首先借助基础模型去提取局部视觉特征,进而识别文字区域以及基本结构,这一阶段着重于对细节的捕捉,恰似一开始要瞧清每一个字的笔画 。
接着引入大型模型来开展全局理解,剖析整页内容之中的逻辑关系以及语义连贯性。两个阶段各自履行职责,既对细节精度予以保证,又对整体理解加以确保,从而形成完整的处理链条。
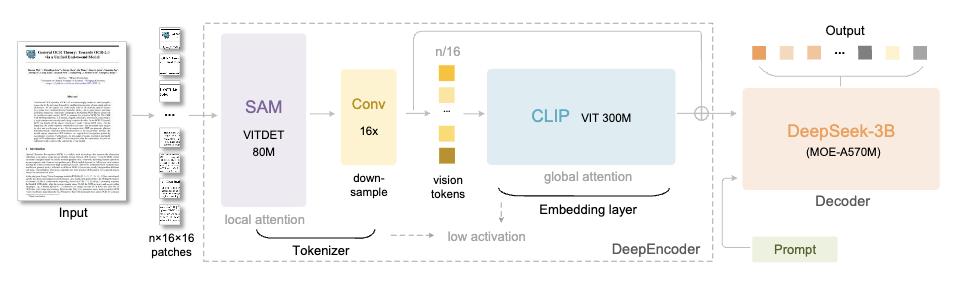
混合专家系统
这一模型运用的是专家混合设计方式,包含有64个专业处理模块,每一次仅会激活其中6个核心模块,并且搭配2个共享模块。这样设计能够让系统在有着30亿参数规模表达能力时, 还使其实际运行效率近乎5亿参数的那种小型 模型 处的情况 。
使模型能够依据输入内容所具备的特征,凭借动态选择机制灵动地调配最为适宜的处理模块。如此这般的灵活进行配置,不但节省了计算资源,而且还维持住了解析精度,于效率以及效果之间探寻到了平衡点。
训练数据构建
训练数据被划分成粗标注与精标注这两类,经由解析PDF文档直接获取粗标注数据,着重训练基础识别能力,这些数据涵盖常见语言,为模型奠定坚实基础。
精细标注的数据,是凭借先进模型予以生成的,其中涵盖着检测与识别相互交织起来的高质量样本。针对小众语言而言,团队研发出了数据增强循环机制,借助模型之间相互促进,最终累积起了60万条训练样本。
深度解析能力
该系统不但能够识别文字,而且拥有深度解析功能,只要有着统一指令,便可以把复杂图像里的结构化信息提取出来,不管是表格、图表,亦或是混合版面,它都能够准确地还原其内容组织逻辑。
凭借这样的一种能力,模型得以理解文档内含的带有深度意义的语义构造,它不但能够将文字读取出来,而且还能够对于这些被读取的文字身处文档里所具备的功能角色予以理解,进而为后续展开的信息予以处理搭建起基础架构基础。
未来应用前景

研究团队给出了更为大胆的设想,那就是运用光学压缩去模拟人类的记忆机制,近期的内容要维持高精度,而历史信息则进行压缩存储,这样的机制有希望突破上下文长度的限制。
日后打算推行数字跟光学文本交互训练,实施更严谨的测试评估。要是这些探寻达成成功,会全盘改变长文本处理模式,给人工智能进展开辟新空间。
使用长文档处理工具之际,最为经常碰到的困扰是哪些呢?欢迎将你的经历予以分享,要是感觉本文具备帮助作用,那就请点赞予以支持吧!
发表评论